Understanding the impact of tariffs on your business requires more than just speculation, it demands a data-driven approach. Tariffs can disrupt supply chains, alter pricing strategies, and influence overall market conditions. By monitoring key macroeconomic and financial indicators, businesses can quantify these effects and make informed decisions.
If you’d like to see the impact of tariffs on your own forecasting models, here are some of the most valuable signals:
Advance U.S. International Trade in Goods: Imports and Exports
U.S. Imports & Exports by Country
U.S. Exports & Imports by Commodity
U.S. Exports of Goods by F.A.S. Basis by Country
Trade Balance
Import & Export Price Indexes
Federal Tax Receipts: Taxes on Production and Imports
U.S. Imports & Exports
Financial Markets
How Ready Signal Helps Businesses Identify the Right Indicators to Measure Tariff Impacts
At Ready Signal, we specialize in helping businesses identify the most relevant data signals to answer their specific questions and solve critical challenges. Our team has worked closely with several organizations to integrate tariff-related economic indicators into their forecasting models, enabling them to quantify the impact of recent trade policies with greater accuracy.
Below is a real-world example of how our customers are leveraging these insights to navigate the effects of tariffs on their business.
Ready Signal’s AI-Powered Insights: Linking the Trade Balance to Business Performance
A powerful leading indicator of tariff effects is the U.S. trade balance. A measure that captures real-time shifts in imports and exports.
Recent tariffs and the anticipation of additional trade barriers have dramatically widened the U.S. trade deficit. In January 2025, the deficit surged to a record $131.4 billion, marking a 34% increase from the previous month. The primary driver? A 10% rise in imports, as businesses rushed to stockpile goods ahead of tariff hikes.
Even visually, in the graph above, we can see how the DJIA’s performance decline lagged by about a month behind the significant inflection point in the Trade Balance, illustrating how trade disruptions or even the threat of trade disruptions translates into broader market reactions.
We can now look at the Trade Balance in the context of the Dow Jones Industrial Average (DJIA) as a proxy for overall business performance.
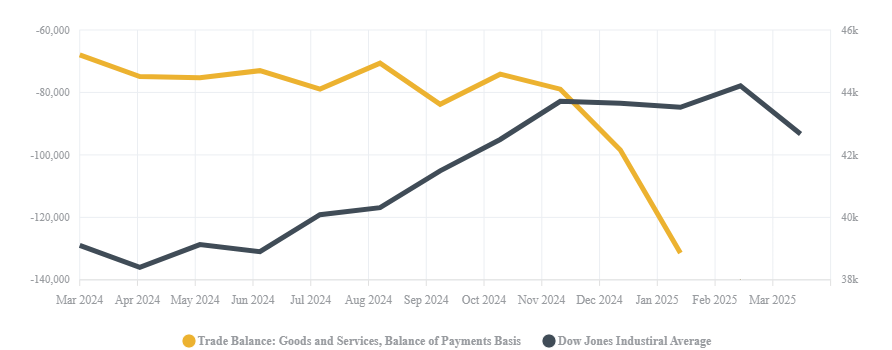
This turbulence is now rippling through financial markets, particularly the DJIA, as businesses face higher costs, supply chain disruptions, and shifting global trade patterns. Investor confidence has weakened, leading to increased market volatility. Economists warn of a growing risk of recession, fueled by uncertainty surrounding tariff policies. Major indices, including the DJIA and S&P 500, have already experienced declines, while leading financial institutions continue to downgrade growth forecasts in response to these economic shifts.
What This Means for Your Business
The drastic changes in the trade balance, driven by front-loaded imports and shifting global trade conditions, signal the real-time impact of tariffs on businesses.
By identifying the key leading indicators that influence your business and serve as early signals of market reactions to tariffs and other economic events, you can anticipate shifts before they happen. Integrating these insights into your forecasting and strategic planning enables you to take a proactive, data-driven approach—helping you prepare for potential disruptions, adjust strategies accordingly, and stay ahead in an unpredictable economic environment.
With our generous free trial, you can sign up, download these features, and see the impact in your forecasts the same day. Sign up today!